iclr spotlight reviewer评分 6888
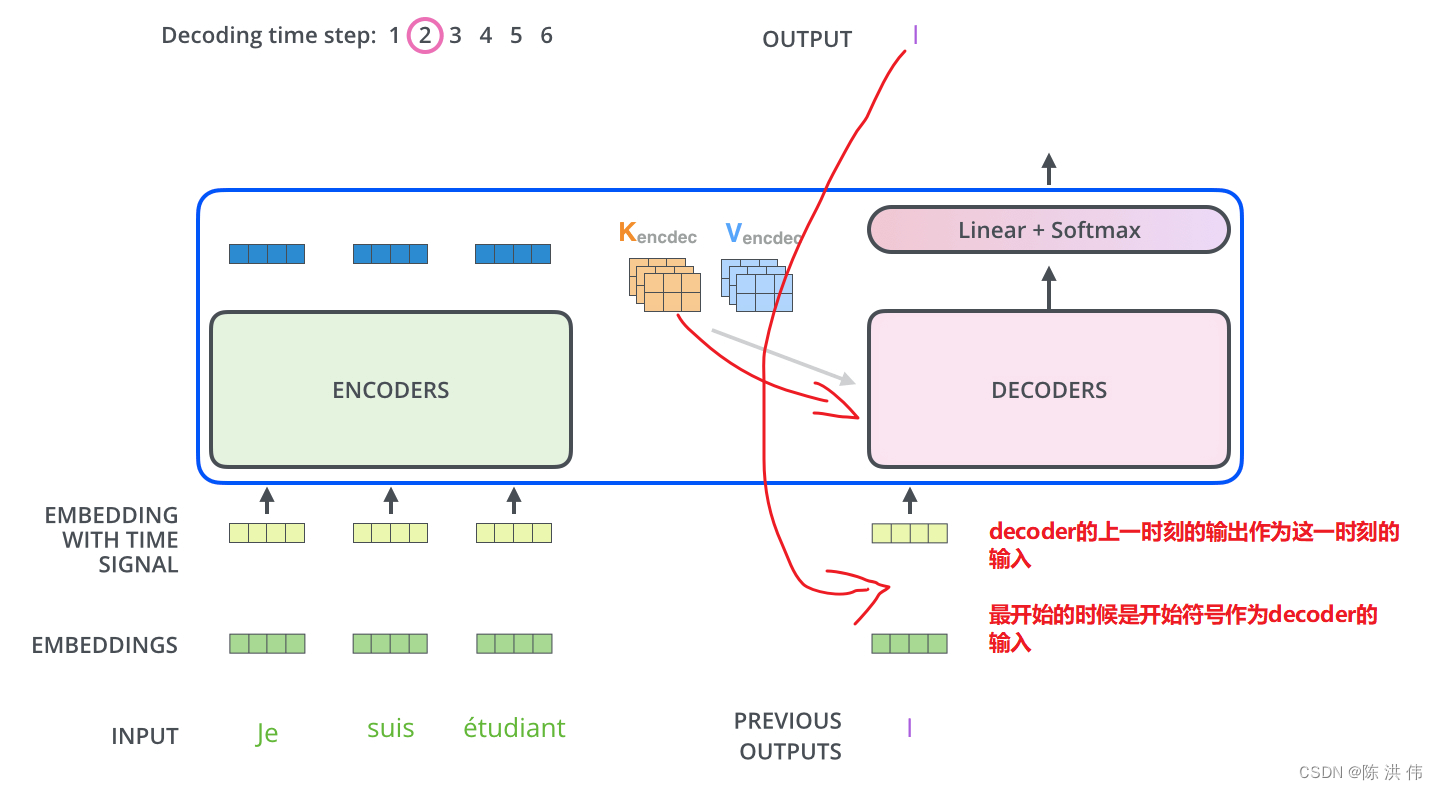
- 论文研究了一个具有H个头的单层多头注意力(MHA)模块的记忆容量
- 它接受一个n×d token/上下文矩阵作为输入(n个token,每个token的embedding维度为d),以及一个d×1的查询向量
- 论文首先引入了一组新的输入数据假设,与普适位置假设相比更为宽松
- 第一个假设要求所有查询向量的Kruskal秩至少为n
- 第二个假设需要每个示例的上下文向量线性独立
- 在上述这组温和的假设下,论文证明了一个单层MHA模块
- 这个模块具有H个头,嵌入维度d,key/query的维度 dh,value 维度dv,上下文大小n < d,输出维度dout ≤ dv
- 也即一共有O(Hd(dh + dv))可训练参数
- ——>能够记住Ω (H min(n, dh))个输入示例
- 不同注意力头在记住不同示例集时扮演不同角色——>每个头单独“负责”记住min(n, dh) - 1个示例
- 通过利用softmax的饱和属性并引入特定的键-查询权重调整,为个别头设计了所需的softmax logits,同时确保对其他示例的干扰最小